Druid 高性能實時分析數(shù)據(jù)存儲系統(tǒng)概覽
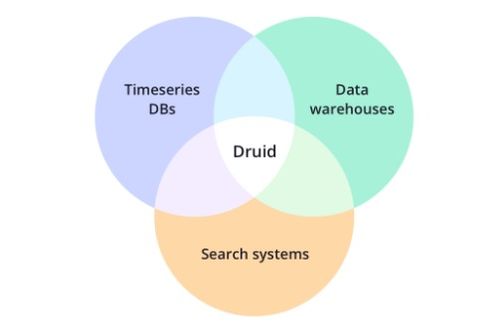
Druid 是一個開源的、分布式的、列式存儲的實時分析數(shù)據(jù)系統(tǒng),專為處理大規(guī)模數(shù)據(jù)集的低延遲查詢而設計。它廣泛應用于在線分析處理(OLAP)、業(yè)務智能和實時監(jiān)控場景。
主要特點
- 實時數(shù)據(jù)攝入:支持從流式數(shù)據(jù)源(如Kafka、Kinesis)和批處理數(shù)據(jù)源(如HDFS)實時攝入數(shù)據(jù)。
- 低延遲查詢:提供亞秒級的查詢響應時間,適用于交互式分析。
- 高可用性和可擴展性:通過分布式架構(gòu)支持水平擴展,自動處理節(jié)點故障。
- 列式存儲:優(yōu)化了聚合查詢和掃描操作,減少I/O開銷。
- 時間序列優(yōu)化:內(nèi)置對時間序列數(shù)據(jù)的支持,便于按時間范圍查詢和聚合。
- 靈活性:支持多種數(shù)據(jù)格式和查詢語言(如SQL和原生JSON查詢)。
- 多租戶支持:可隔離不同用戶或應用的數(shù)據(jù)和查詢負載。
設計原則
Druid 的設計遵循以下核心原則:
- 快速查詢:通過預聚合、索引和列式存儲來最小化查詢延遲。
- 可擴展性:采用無共享架構(gòu),允許動態(tài)添加節(jié)點以處理增長的數(shù)據(jù)量和查詢負載。
- 容錯性:系統(tǒng)自動復制數(shù)據(jù)和重新分配任務,確保在節(jié)點故障時持續(xù)運行。
- 簡單性:提供直觀的數(shù)據(jù)模型和API,簡化開發(fā)和維護。
- 云原生:支持在容器化環(huán)境(如Kubernetes)中部署,適應現(xiàn)代基礎設施。
架構(gòu)
Druid 的架構(gòu)由多個協(xié)調(diào)組件組成,包括:
- Master 節(jié)點:負責數(shù)據(jù)管理和任務協(xié)調(diào),包括Coordinator(管理數(shù)據(jù)段)和Overlord(控制數(shù)據(jù)攝入)。
- Data 節(jié)點:處理數(shù)據(jù)存儲和查詢,包括Historical(存儲歷史數(shù)據(jù))和MiddleManager(處理實時數(shù)據(jù)攝入)。
- Query 節(jié)點:Broker 節(jié)點接收查詢請求,并將其路由到相應的Data節(jié)點。
- 元數(shù)據(jù)存儲:使用外部數(shù)據(jù)庫(如MySQL或PostgreSQL)存儲元數(shù)據(jù)信息。
- 深度存儲:依賴分布式文件系統(tǒng)(如HDFS或S3)進行數(shù)據(jù)備份和持久化。
這種模塊化設計允許獨立擴展各個組件,提高了系統(tǒng)的靈活性和可靠性。
數(shù)據(jù)結(jié)構(gòu)
Druid 的數(shù)據(jù)模型基于以下概念:
- 數(shù)據(jù)源:類似于數(shù)據(jù)庫中的表,每個數(shù)據(jù)源包含多個數(shù)據(jù)段。
- 數(shù)據(jù)段:數(shù)據(jù)的基本存儲單元,按時間分區(qū)并包含列式數(shù)據(jù)。
- 列類型:支持多種類型,如時間戳、維度(用于分組和過濾)、度量(用于聚合計算,如求和、計數(shù))。
- 索引:使用位圖索引優(yōu)化維度列的過濾操作,提升查詢性能。
數(shù)據(jù)以時間戳為主鍵組織,便于時間范圍查詢和聚合。
簡單入門Druid
要快速開始使用Druid,可以按照以下步驟:
- 安裝:從Apache官網(wǎng)下載Druid發(fā)行版,或使用Docker鏡像快速部署。
- 啟動服務:運行單機模式(適用于測試)或分布式模式(適用于生產(chǎn))。
- 攝入數(shù)據(jù):使用內(nèi)置控制臺或API從文件(如CSV、JSON)或流式源(如Kafka)攝入數(shù)據(jù)。
- 查詢數(shù)據(jù):通過REST API或SQL接口執(zhí)行查詢,例如使用
SELECT * FROM datasource WHERE __time >= '2023-01-01'。 - 監(jiān)控:利用Druid的控制臺和日志監(jiān)控系統(tǒng)狀態(tài)和查詢性能。
數(shù)據(jù)處理和存儲支持服務
Druid 提供全面的數(shù)據(jù)處理和存儲支持:
- 數(shù)據(jù)處理:支持數(shù)據(jù)轉(zhuǎn)換、過濾和聚合在攝入階段完成,減少查詢時的計算負載。可通過Apache Kafka、Amazon Kinesis等集成實時流處理。
- 存儲服務:數(shù)據(jù)持久化在深度存儲(如云存儲或HDFS)中,并自動復制以確保高可用性。Historical節(jié)點管理本地緩存以加速查詢。
- 查詢服務:通過Broker節(jié)點提供統(tǒng)一的查詢接口,支持標準SQL和原生查詢,并與工具如Grafana、Superset集成。
- 運維支持:包括自動數(shù)據(jù)段平衡、備份和恢復機制,以及監(jiān)控指標導出到Prometheus等系統(tǒng)。
Druid 是一個強大的實時分析平臺,結(jié)合了高性能、可擴展性和易用性,適用于大數(shù)據(jù)環(huán)境下的快速洞察和決策支持。
如若轉(zhuǎn)載,請注明出處:http://m.gnnx.com.cn/product/14.html
更新時間:2026-01-07 02:41:01